
안녕하세요 여러분! 드디어 좀 흥미있는 주제들이 나오시 시작합니다.
오늘은 8단원 Arrays 배열을 가져왔습니다. 자 그럼 드가봅시다!!
Chap8. Arrays.
If a program manipulates a large amount of data, it does so in a small number of ways.
Intro
지금까지 우리가 살펴본 변수는 전부 스칼라(scala) 이다. 스칼라는 한개의 데이터를 가질 수 있다.(capable of holding a single data item) 또한 C는 값들의 모음을 저장할 수 있는 변수의 집합을 지원한다.(C also supports aggregate variables, which can store colllections of values.) C에는 두 종류의 집합이 있는데 바로 배열과 구조체이다. 이번 단원에서는 어떻게 배열을 선언하고 사용할 수 있는지 살펴볼 것이다. 이번 단원은 다차원 배열보다 더 큰 역할을 차지하고 있는 일차원 배열을 중점으로 배울 것이다.
8.1 One-Dimensioal Arrays(일차원 배열)
배열은 같은 타입의 데이터 값들을 가지고 있는 자료구조이다. 이러한 값들은 원소(elements) 라고 불리며, 배열 안에서의 위치를 기준으로 개별적으로 선택될 수 있다.
가장 간단한 배열의 형태는 일차원 배열이다. 일차원 배열의 원소는 한개의 행을 따라 차례대로 나열되어 있다.
a라는 이름을 지닌 일차원 배열을 시각적으로 표현하면 다음과 같다.

배열을 선언하기 위해서 우리는 반드시 배열의 원소들의 타입과 원소의 개수를 명시해주어야 한다. 예를 들어, a라는 배열이 int 타입의 원소 10개를 가지고 있다고 선언하기 위해선, 다음과 같이 적어야한다.
int a[10];배열의 원소는 아무 타입이나 가능하다. 배열의 길이 역시 아무 상수표현식을 써도 상관없다. 프로그램이 나중에 바뀔 때, 배열 길이도 조정되어야 하는 경우 매크로로 배열길이를 정의해놓는 것은 아주 좋은 습관이다!
(사실 하이레벨 프로그래밍 언어에서는 이렇게 안하죠 ..!)
#define N 10
...
int a[N];
Array Subscripting
배열의 특정 원소에 접근하기 위해서는, 우리는 배열 이름 뒤에 중괄호로 둘러싸인 정수값을 적으면 된다. 이는 subscripting 혹은 indexing the array 이라고 불린다.) 배열의 원소들은 항상 0부터 자리매김된다. 따라서 배열의 길이가 n 인 원소들은 0 부터 n-1 까지 인덱싱된다. 예를 들어, 만약 a가 10개의 원소를 가졌다면, 그들은 다음 그림처럼 각각 a[0], a[1], a[2], .... , a[9] 로 지정된다.
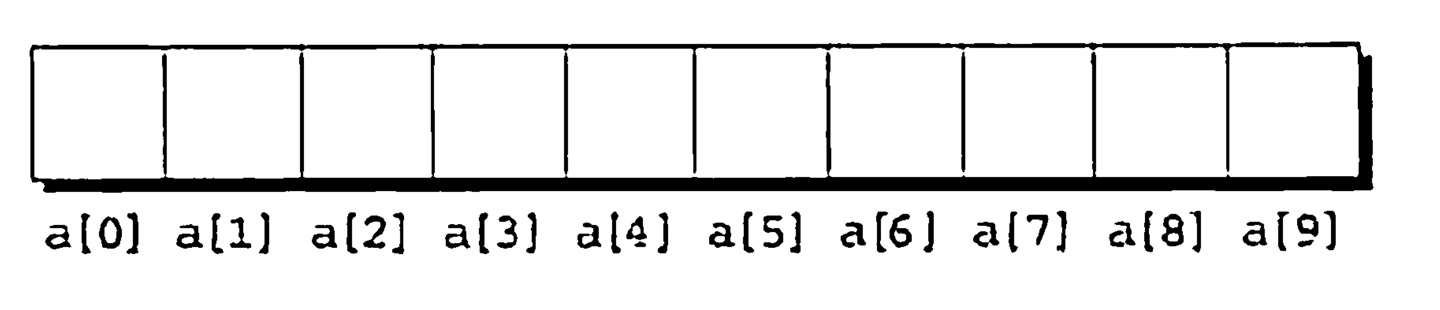
a[i] 형태의 표현식은 lvalues이다! 따라서 이런 형태는 변수와 똑같이 사용할 수 있다.
a[0] = 1;
printf("%d\n", a[5]);
++a[i];일반적으로, 만약 배열이 T라는 타입의 원소들을 포함하고 있다면, 배열의 각각의 원소들은 T 타입의 변수처럼 다뤄진다. 위 예시에선, a[0] 과 a[5], a[i] 는 모두 int 타입 변수처럼 행동하고 있다.
배열과 for 루프는 서로 밀접히 연관된다. 많은 프로그램에서 for 반복문은 배열의 모든 원소들에 대해 특정한 작업을 수행하는 역할을 지닌다. 여기 길이가 N 이고 이름이 a인 배열에 행해지는 여러 C 관용구 들이 있다.
for(i = 0; i < N; i++) // clears a
a[i] = 0;
for(i = 0; i < N; i++) // reads data into a
scanf("%d", a[i]);
for(i = 0; i < N; i++) // sums the elements of a
sum += a[i];scanf 를 쓸때 일반 변수들과 마찬가지로 배열의 원소들앞에도 &을 써야한다는걸 짚고 넘어가자!
C는 옳바른 영역내의 subscript를 썼는지 검사할 의무는 없다. 따라서 만약 subscript 가 범위 바깥을 넘어가면, 이 경우 프로그램의 행동은 정의되지 않았다. (if a subscript goes out of range, the program's behavior is undefined)
(undefined behavior 라는 뜻임.)
다음의 예시는 이러한 실수 때문에 생기는 꽤 기이한 경우이다.
int a[10], i;
for(i = 1; i <= 10; i++)
a[i] = 0;특정 컴파일러에서 이 for문은 무한루프를 야기한다! 왜 그럴까?
만약 i 가 10 에 다다르면, 프로그램은 a[10]에 0을 저장한다. 그러나 a[10]은 존재하지 않기 때문에, 0이 a[9] 옆에 위치한 메모리에 저장된다. 만약 i 가 a[9] 옆에 저장되어있었다면 i는 0으로 갱신될것이고 이는 루프가 무한번 반복하게 한다.
배열의 subscript 는 아무 정수 표현식이면 상관없다.
a[i + j * 10] = 0;부수효과(side effect)를 지닌 subscript 를 쓸때는, 조심해서 사용하도록 하자. 예를 들면,
i = 0;
while (i < N)
a[i] = b[i++];이 코드의 결과를 예측할 수 있는가?
a[i] = b[i++] 라는 표현식은 i 값에 접근하고 동시에 i의 값을 표현식 어딘가에서 바꾸기 때문에 4.4장에서 봤듯이 이는 undefined behavior를 불러일으킨다. 당연히, 우리는 이러한 문제를 증감연산자를 따로 떼냄으로써 해결할 수 있다.
for (i = 0; i < N; i++)
a[i] = b[i];Array Initialization
배열은 다른 변수들과 마찬가지로, 선언될 때 초기값을 정할 수 있다. 이 룰은 그런데 살짝 까다로운 부분이 있다!
가장 흔한 배열 초기화의 형태(initializer's form)는 다음과 같다. 중괄호안에 콤마로 구분되는 상수표현식들의 리스트를 넣은 형태이다.
int a[10] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};이 때 배열의 길이보다 initializer가 작다면, 초기화되지 않은 부분들은 0 값을 갖게 된다.
int a[10] = {1, 2, 3, 4, 5, 6};
//initial value of a is {1, 2, 3, 4, 5, 6, 0, 0, 0, 0}이런 특성을 이용해 우리는 배열의 모든 원소를 0으로 초기화할 수 있다.
int a[10] = {0};
// initial value of a is {0, 0, 0, 0, 0, 0, 0, 0, 0, 0}initializer가 아예 비어져있는것은 허용되지 않으므로, 중괄호안에 0 한개를 넣었다는것을 짚고 넘어가자.
initializer가 배열 길이보다 길면 안된다는것도 조심하자.
만약 initializer 가 존재한다면, 배열의 길이는 생략되도 된다.
int a[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};컴파일러는 initializer 의 길이를 배열이 얼마나 긴 지 판단할때 사용한다. 배열은 여전히 고정된 갯수의 원소를 가지고 있다.
배열을 초기화할 때 몇 개의 원소들만 초기화하고 나머지는 기본값으로 놔두고 싶을 때 가 있다. 이럴땐 어떻게 해야할까? 이를테면, 다음과 같은 상황이다.
int a[15] = {0, 0, 29, 0, 0, 0, 0, 0, 0, 7, 0, 0, 0, 0, 48};여기서는 그냥 초기화했지만 만약 배열 길이가 200 정도로 늘어나면 적기가 힘들것이다.
그래서 C99 에서는 designated initializers 라는것을 지원한다. designeated initializer를 사용하여 위 예시를 다시 적을 수 있다.
int a[15] = {[2] = 29, [9] = 7, [14] = 48};중괄호안의 각각의 숫자들은 designator 라고 불린다. (2, 9, 14)
또한, 초기화할때 중괄호 안의 순서들도 상관없다. 다음과 같이 적어도 된다.
int a[15] = {[14] = 48, [9] = 7, [2] = 29};designator 들은 반드시 정수형태의 상수 표현식이어야 한다. 만약 배열의 길이가 n 이라면, 각각의 designator 들은 반드시 0 과 n - 1 에서의 숫자들이어야 한다. 만약, 배열의 길이가 생략된 경우라면, designator 는 음수가 아닌 정수라면 어떤 값이와도 상관 없다. 후자의 경우, 컴파일러는 제일 큰 designator 로부터 배열의 길이를 추측할것이다. 예를 들어,
int b[] = {[5] = 10, [23] = 13, [11] = 36, [15] = 29};이 경우 가장 큰 designator 는 23이다. 이 경우 배열의 길이는 24가 된다.
배열의 initializer 를 적을때 element - by - element 방식과 designated 방식 두 개를 섞어서 사용해도 괜찮다.
(An initiailzer may use both the older(elemnet - by element) technique and the newer(designated) technique)
int c[10] = {5, 1, 9, [4] = 3, 7, 2, [8] = 6};배열 c의 원소들은 차례대로 5, 1, 9, 0, 3, 7, 2, 0, 6, 0 가 된다.
Program - Checking a Number for Repeated Digits
어떤 숫자에서 겹치는 숫자가 있는지 없는지 판단해주는 프로그램을 짜볼것이다. 유저가 숫자를 입력하면, 프로그램은 겹치는 숫자가 있으면 Reapeated digit 이라고 출력하고, 겹치는 숫자가 없으면 No repeated digit 이라고 출력한다.
Enter a number : 28212
Repeated digit
28121 는 겹치는 숫자인 2를 가지고 있다. 9357 은 가지고 있지 않다. 한 번 짜보고 다시 와보자!
.
.
.
#define _CRT_SECURE_NO_WARNINGS // visual studio...
#include <stdbool.h>
#include <stdio.h>
int main(void)
{
bool digit_seen[10] = { false };
int digit;
long n;
printf("Enter a number : ");
scanf("%d", &n);
while (n > 0)
{
digit = n % 10;
if (digit_seen[digit])
break;
digit_seen[digit] = true;
n /= 10;
}
if (n > 0) printf("Repeated digit \n");
else printf("No repeated digit \n");
return 0;
}
프로그램은 입력으로 들어온 숫자에서 어느 숫자가 쓰였는지 알기 위해서 Boolean 값들의 배열을 이용한다.
digit_seen 배열은 10개의 숫자에 대응하는 0 부터 9까지 인덱싱 되어있다.
digit_seen을 초기화할때 첫번째 원소만 false로 초기화한것 같지만, 배열의 모든 원소는 false로 초기화된다.
컴파일러는 자동으로 나머지 원소들을 false를 의미하는 0으로 만들것이다.
우선 n 을 프로그램이 읽으면, 프로그램은 n의 각각의 자릿수를 digit 에 저장한다. 그리고 이를 digit_seen 배열에 접근하기 위한 인덱스로 사용한다.
겹치는지 상태를 나타내는 bool isRepeated = false 라고 하는것보다 if(n > 0) else 문을 사용해 반복되는 숫자인지 반복되지 않는 숫자인지 검사하는 로직도 살펴보고 넘어가자.
만약 <stdbool.h> 를 컴파일러가 지원하지 않는다면,
#define true 1
#define false 0
typedef int bool;main 함수위에 이렇게 적어주면 된다.
Using the sizeof Operator with Arrays
sizeof 연산자는 배열의 크기를 바이트 단위로 결정할 수 있다. 만약 a가 10개의 정수로 이루어진 배열이라면 각각의 정수가 4 바이트를 차지한다는 가정하에 sizeof(a) 는 40 일것이다.
우리는 또한 sizeof 연산자를 a[0] 같은 배열 원소의 크기를 알기 위해 사용할 수 있다. 그리고 배열의 크기를 원소의 크기로 나누면 배열의 길이가 나온다.
sizeof(a) / sizeof(a[0])
이 표현식을 배열의 길이가 필요할 때 쓸 수 있다.
for (i = 0; i < sizeof(a) / sizeof(a[0]); i++)
a[i] = 0;이 기술을 사용할 때는, 배열의 길이가 바뀌어도 반복문을 수정할 필요가 없다.
배열의 길이를 나타내기 위해 매크로를 쓰는것은 좋은 전략이지만, sizeof 테크닉을 사용하는것이 약간 더 좋다.
왜냐하면 매크로 이름을 기억할 필요가 없어지기 때문이다. (코드 쓰다가 까먹을 수 있다!)
다만 한 가지 짜증나는 경우가 발생할 수 있는데, 특정 컴파일러들은 sizeof(a) / sizeof(a[0]) 이 표현식에 대해 경고메시지를 띄울 수 있다는 것이다. 변수 i 는 아마 int 타입(signed)으로 선언될것인데, 그에 비해 sizeof 연산자는 size_t 타입(unsigned)의 값을 가지기 때문이다. 비록 위 예시 같은 경우 i 와 sizeof(a) / sizeof(a[0]) 두 표현식 모두 음수가 아니지만, 7.4 장에서 부호있는 정수와 부호없는 정수를 비교하는 것은 매우 위험함을 짚고 넘어갔었다!
위 경고를 피하기 위해, 우리는 캐스팅을 사용할 수 있다.
for (i = 0; i < (int) (sizeof(a) / sizeof(a[0])); i++)
a[i] = 0;조금 거추장스럽다면, 다음과 같이 매크로를 사용할 수 있다.
#define SIZE (int) (sizeof(a) / sizeof(a[0]))
for (i = 0; i < SIZE; i++)
a[i] = 0;그런데 이렇게 쓰면 다시 매크로를 사용하는 꼴 아닌가! 이러면 sizeof 의 장점이 뭔가.
이에 대해서는 이후의 챕터에서 다루기로 하자.(미리 스포하자면 매크로에 파라미터를 추가하는것이다)
8.2 Multidimensional Arrays(다차원 배열)
배열은 일차원이 아닌 다차원으로도 사용될 수 있다. 예를 들어, 다음의 선언은 이차원 배열을 만들어낸다.(수학적 용어로는 행렬)
int m[5][9];배열은 5개의 행과 9개의 열을 가지고 있다. 다음 그림처럼 행과 열 모두 0부터 인덱싱된다.
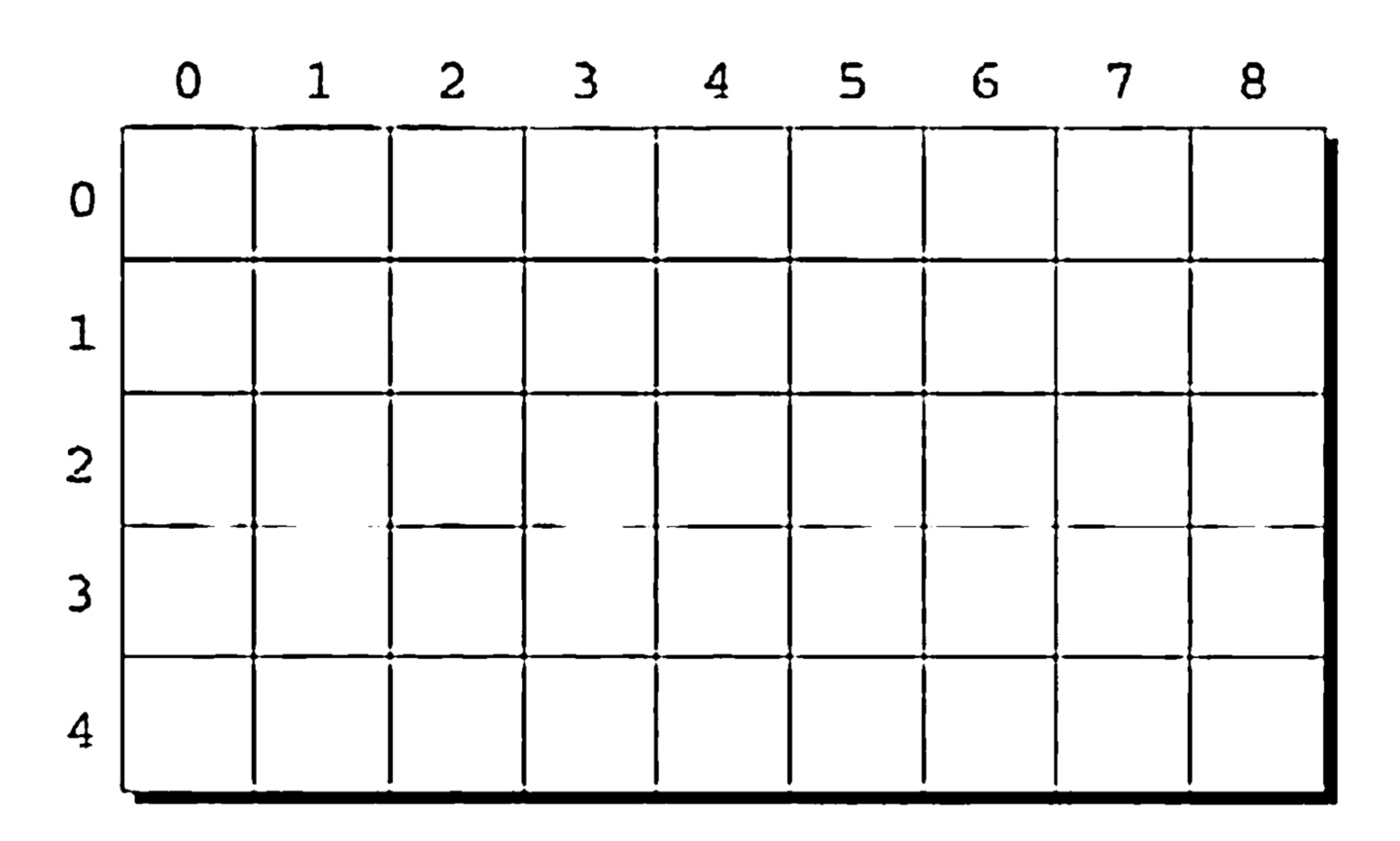
i 번째 행과 j 번째 열에 위치한 m 의 원소에 접근하기 위해서 우리는 반드시 m[i][j] 라고 써야한다.
m[i] 라는 표현식은 m의 i번째 행을 지정하고, m[i][j] 는 이 i 번째 행에서 j번째 원소를 선택한다.
우리는 비록 이차원 배열을 테이블 형태로 시각화 하였지만, 사실 이는 배열이 컴퓨터 메모리에 저장되는 방식이 아니다.
C는 배열을 행 우선순위에 의해 저장한다.(C stores arrays in row-major order) 0번째 행이 먼저오고 그 다음 1번째 행, 2번째 행으로 계속된다. 예를들면, 이차원 배열 m은 다음 그림과 같이 저장된다.
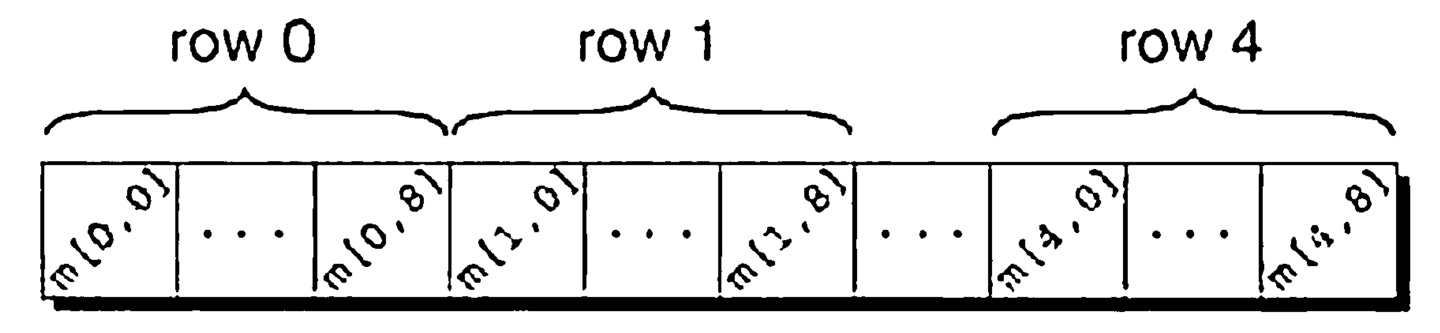
우리는 이런 디테일을들을 보통 무시할것이지만, 가끔씩 이는 우리 코드에 영향을 미칠것이다.
이를테면, 다차원 배열을 다룰때 이중 for문을 쓰는 경우이다. 예를 들어, identity matrix(수학에서는 주 대각선의 성분이 1이고 나머지가 0이면 identity matrix 라고 한다.) 각 원소에 접근할때 배열이 메모리에 저장되는 방식을 생각하며 for문을 작성하면 다음과 같다.
#define N 10
double ident[N][N];
int row, col;
for (row = 0; row < N; row++)
for (col = 0; col < N; col++)
if (row == col)
ident[row][col] = 1.0;
else
ident[row][col] = 0.0;다차원 배열은 사실 C에서는 다른 프로그래밍 언어에서만큼 큰 역할을 하지는 않는다. 왜냐하면 C는 다차원 데이터를 다루는 더 유연한 수단을 제공하기 때문이다. 바로 배열의 포인터이다.(arrays of pointer).
Initializing a Multidimensional Array
2차원 배열의 initializer 는 1차원 배열의 initializer를 중괄호 안에 품음으로써 작성할 수 있다. 예를 들어,
int m[5][9] = {{1, 1, 1, 1, 1, 0, 1, 1, 1},
{0, 1, 0, 1, 0, 1, 0, 1, 0},
{0, 1, 1, 1, 0, 1, 1, 1, 0},
{0, 0, 0, 1, 0, 1, 0, 0, 0},
{0, 1, 0, 1, 0, 1, 0, 1, 0}};각각의 안에 위치한 initializer는 행렬의 한 행의 값들을 제공한다. C는 다차원 배열에서 initializer를 축약할 수 있는 여러 방법을 제공한다.
만약, initializer 가 다차원 배열의 원소들을 전부 초기화 하지 않는다면, 초기화하지 않은 부분들은 0 값으로 채워진다.
int m[5][9] = {{1, 1, 1, 1, 1, 0, 1, 1, 1},
{0, 1, 0, 1, 0, 0, 1, 0},
{0, 1, 1, 1, 0, 1, 1, 1, 0},
{0, 0, 0, 1, 0},
{0, 1, 0, 1, 0, 1, 0, 1, 0}};
int m[5][9] = {{1, 1, 1, 1, 1, 0, 1, 1, 1},
{0, 1, 0, 1, 0, 1, 0, 1, 0},
{0, 1, 0, 1, 0, 1, 0, 1, 0}};위 두 경우 모두 초기화 하지 않은 원소들은 0으로 초기화된다.
다음 코드 처럼 안쪽의 괄호들을 생략할 수 도 있다.
int m[5][9] = {1, 1, 1, 1, 1, 0, 1, 1, 1,
0, 1, 0, 1, 0, 1, 0, 1, 0,
0, 1, 1, 1, 0, 1, 1, 1, 0,
0, 0, 0, 1, 0, 1, 0, 0, 0,
0, 1, 0, 1, 0, 1, 0, 1, 0};Constant Arrays
일차원 배열이든 다차원 배열이든, const 키워드와 같이 선언함으로써 상수(constant) 처럼 사용할 수 있다.
const char hex_chars[] = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '0',
'A', 'B', 'C', 'D', 'E', 'F'};
const 로 선언된 배열은 반드시 수정되어선 안된다. 컴파일러는 배열의 원소를 바꾸려는 시도를 바로 캐치할것이다.
배열을 const 로 선언하는것은 꽤 장점이 많다. 읽는 사람으로 하여금 이 배열은 바뀌어선 안된다는것을 알려주기도 하고, 이 배열을 수정할 의도가 없다는 것을 통해 컴파일러가 에러를 잡아내게 할 수 도 있다.
const 는 단지 배열에만 그치지 않는다. 어떤 변수에라도 적용할 수 있다. 이후의 챕터에서 살펴보자.
8.3 Variable-Length Arrays(C99)
8.1 장에서 배열의 길이는 반드시 상수 표현식에 의해 명시되어야 한다고 했었다. 그런데 C99 에서는 가끔 이를 허용해준다!(In C99, however, it's sometimes possible to use an expression that's not constant).
다음의 코드를 보자.
#include <stdio.h>
int main(void)
{
int n;
scanf("%d", &n);
int a[n]; // C99 only
scanf("%d", &a[0]);
printf("%d", a[0]);
}
위의 코드에서 배열 a가 바로 가변길이배열(variable - length array) 의 예시이다.(혹은 VLA 라고 줄여서 말하기도 한다.)
VLA의 길이는 프로그램이 컴파일될때 계산되지 않고, 프로그램이 실행될 때 계산된다. VLA의 주요한 장점은 프로그래머가 배열을 선언할때 임의의 길이를 설정하지 않다도 된다는 점이다. 그 대신에, 프로그램 자체가 정확히 몇 개의 원소가 필요한지 계산할 수 있다. (the program itself can calculate exactly how many elements are needed.)
int a[3 * i + 5];
int b[j + k];
int c[m][n];또한 표현식으로도 길이를 설정할 수 있고, 다차원 배열에서도 쓰일 수 있다.
(사실 하이레벨 언어에서는 자연스러운건데 말이죠!)
VLA의 주요한 한계점은 바로 정적인 저장 기간을 가질 수 없다는 점이다. (The primary restriction on VLAs is that they can't have static storage duration). 다른 한계점은 VLA 는 initializer 를 가질 수 없다는 점이다.
가변 길이 배열은 main 함수 이외의 함수에서 자주 등장한다. VLA 의 큰 장점 중 하나는, 만약 VLA가 함수 f에 속하는 경우 f가 호출될때마다 다른 길이를 가지게 할 수 있다는 점이다. 우리는 이런 특성을 9.3절에서 다룰것이다!
Q&A
Q : 왜 배열의 인덱싱(subscript)은 1 이 아니라 0 부터 시작하나요?
A : 0부터 시작하게 하면 컴파일러를 좀 더 단순화시켜준단다. 그리고 조금 더 빠르게 동작하게 할 수 있어.
Q : 0 부터 9 까지의 숫자로 접근안하고 1부터 10까지로 접근하려면 어떻게 하나요?
A : 잘 알려진 트릭이 있다! 바로 배열 길이를 11로 설정하는거야. 그리고 0번째 원소는 무시하면 된단다.
Q : a, b 배열이 있을 때 a = b 처럼 배열을 복사하려는데 에러가 떠요! 어떻게 해야 하나요?
A : 사실,
a = b; // a and b are arrays이 표현식은 겉보기엔 타당해보이지만, 사실은 틀린 표현일세. 왜 틀린 표현일까? 그 이유는 명확하진않네.
이는 C에서 배열과 포인터의 고유한 관계때문에 그런것일세. 12장에서 자세히 다뤄주겠네.
한 배열을 다른 배열로 복사하는 가장 간단한 방법은 하나씩 반복문안에서 복사해주는 것일세.
for (i = 0; i < N; i++)
a[i] = b[i];다른 방법은 <string.h> 헤더 안에 있는 memcpy ("memory copy") 함수를 사용하는 것일세.
memcpy 는 한 곳에서 다른곳으로 바이트 그 자체를 복사하는 로우레벨 함수야. b를 a로 복사하기 위해서는 다음과 같이 쓰면 된다네.
memcpy(a, b, sizeof(a));많은 프로그래머들이 memcpy 를 선호하지. 왜냐면 보통의 반복문보다 빠르거든.
Q : designated initializer 가 배열의 원소를 중복해서 초기화 하는것같아요. 결과가 제 생각대로 안나오더라구요.
int a[] = {4, 9, 1, 8, [0] = 5, 7};이 선언은 옳은 코드인가요? 옳다고한다면 배열의 길이는 얼마가 되나요?
A : 물론 선언 자체는 틀린게 없어. 아마 몇가지 규칙을 몰라서 그런걸세. 자, 동작 방식은 다음과 같네.
initializer 리스트를 처리할때, 우선 컴파일러는 계속해서 다음으로 초기화될 배열의 원소를 결정한다네.
(the compiler keeps track of which array element is to be initialized next)
보통 초기화할 다음의 원소는 마지막으로 초기화된 원소의 바로 옆에 있는 원소일세.
(Normally, the next element is the one following the element that was last initialized.) 그런데, 만약 지정자(designator)가 초기화 리스트 안에 나타난다면, 초기화되는 다음의 원소는 이미 그 원소가 초기화되었어도 지정자가 가르키는 원소가 된다네.(When a designator appears in the list, it forces the next element be the one represented by the designator, even if that element has already been initialized) 자 무슨 말인지 모르겠지? 자네가 가져온 예시를 들어서 설명해주겠네.
컴파일러가 initializer를 처리하는는 과정을 단계별로 설명하면 다음과 같네.
1, 4가 0번째 원소를 초기화한다. 초기화될 다음 원소는 1번째 원소이다.
2, 9가 1번째 원소를 초기화한다. 초기화될 다음 원소는 2번째 원소이다.
3, 1이 2번째 원소를 초기화한다. 초기화될 다음 원소는 3번째 원소이다.
4, 8이 3번째 원소를 초기화한다. 초기화될 다음 원소는 4번째 원소이다.
5, [0] 지정자(designator)가 초기화될 다음 원소가 0번째 원소가 되게한다. 따라서 5가 0번째 원소를 초기화한다. 이 때 이미 저장된 4를 교체한다. 그리고 초기화될 다음의 원소는 1번째 원소가 된다.
6, 7이 1번째 원소를 초기화한다. 이미 저장되있던 9를 교체한다. 다음으로 초기화될 원소는 2번째 원소이다.
그래서 결과는 다음과 같이 선언한것과 같은 결과를 가져온다네.
int a[] = {5, 7, 1, 8};물론 배열의 길이도 4가 되겠지.
허허 8단원도 끝났네요! 하이레벨 언어는 사용자의 편의를 굉장히 많이 봐주고 있다는 생각이 드네요 ㅎㅎ
읽어주셔서 감사합니다 여러분ㅎㅎ 다음편에서 뵙겠습니다!
'프로그래밍 언어 > C' 카테고리의 다른 글
| [K.N.K C Programming 정리] 연재 무기한 중단 안내 (3) | 2021.06.24 |
|---|---|
| [K.N.King C Programming 정리] Chap 9. Functions (0) | 2021.06.12 |
| [K.N.K C Programming 정리] Chap 7. Basic Types (0) | 2021.06.08 |
| [K.N.K C Programming 정리] Chap 6. Loops (0) | 2021.06.05 |
| [K.N.K C Programming 정리] Chap 5. Selection Statements (3) | 2021.06.05 |


