
안녕하세요 여러분! 오늘은 9단원 Functions 를 가지고 왔습니다!
자 그럼 9단원 Functions 공부하러 가볼까! 좋아 좋아 좋아!
.....
동네놈들 유튜브 재밌더라구요...
Chap 9. Functions
If you have a procedure with ten parameters, you probably missed some.
Intro
2장에서 함수란 단순히 이름을 가지고 있고 한 그룹으로 묶인 일련의 명령들의 집합이라고 배웠었다.
(a function is simply a series of statements that have been grouped together and given a name.)
비록 "함수(function)" 라는 용어 자체는 수학에서 따온것이지만, C 의 함수들은 수학에서의 그것과 똑같은 것은 아니다.
C에서 함수는 인자를 꼭 가질 필요도 없고 결과값을 도출해낼 필요도 없다.(다른 프로그래밍 언어에서는 "function"은 결과값을 반환하지만, "procedure"는 그렇지 않다. C는 이 구분이 명확하지 않긴 하다.)
함수는 C 프로그램에서 빌딩을 쌓는 블록이다! 각각의 함수는 본질적으로 자신만의 선언과 문장을 가진 하나의 작은 프로그램이다. 함수를 이용해 우리는 프로그램을 작은 조각으로 쪼갤 수 있다. 함수는 프로그램에서 중복되는 코드를 제거해줌으로써 지루함을 없애줄 수 있다. 게다가, 함수는 재사용할 수 있다. 한 프로그램에서 쓰인 함수를 다른 프로그램에서도 사용할 수 있다. 지금까지는 단순히 main 함수만 고려했지만, 이번 장에서는 main 이외의 함수를 작성하는 법을 배울것이고 main 함수 자체도 다 깊게 다뤄볼것이다.
9.1 Defining and Calling Functions
함수를 정의하는 공식적인 규칙들을 다루기 전에, 먼저 간단한 함수들을 살펴보고 가자.
두 개의 double 값의 평균값을 구하는 프로그램을 짠다고 해보자. 불행하게도 C 라이브러리는 "average" 함수는 갖고 있지 않다. 그러나 우리는 직접 짤 수 있다. 이는 다음과 같다.
double average(double a, double b)
{
return (a + b) / 2;
}첫 줄 첫 부분의 double 이란 단어는 average 함수의 반환형(return type) 이다. 반환형이란, 함수가 호출될때마다 반환하는 데이터의 타입이다. (return type : the type of data that the function returns each time it's called)
식별자 a 와 b는 함수의 파라미터(매개변수)라고 불린다. 또한 average가 호출될 때 공급되는 두 개의 숫자를 나타낸다.
모든 변수들이 자신의 타입을 가지는 것 처럼 각각의 파라미터 역시 반드시 자신의 타입을 가져야 한다. 위의 예시의 경우 a와 b모두 double 이라는 타입을 가지고 있다. 함수의 파라미터는 본질적으로 변수이다. 다만 초기값이 함수가 호출될때 공급될뿐이다. (A function parameter is essentially a variable whose initial value will be supplied later, when the function is called.)
모든 함수는 중괄호로 둘러싸여진 바디(body, 몸통)라는 실행가능한 부분을 가지고 있다. 함수 average의 바디는 단 한개의 리턴문으로 구성되어 있다. 이 구문을 실행시키는 것은 함수로 하여금 자신이 호출됬던 위치로 다시 돌아가게 한다.(Executing this statement causes the function to "return" to the place from which it was called) (a + b) / 2의 값이 함수에 의해 반환되는 값이다.
함수를 호출하려면 우리는 먼저 함수의 이름을 쓰고, 인자들의 리스트를 써줘야한다. 예를 들어, average(x,y) 는 average 함수의 호출이다. 함수의 로직에 대해 정보를 주기위해 인자들이 사용된다. 예를 들면 이 경우, average함수는 어떤 값의 평균을 구하는 건지 알아야 한다. average(x,y)를 호출하는 것은, x와 y의 값을 파라미터 a와 b로 복사하는 것이다.
그러고나서 average함수의 바디가 실행된다. 인자는 변수일 필요는 없다. 타입만 일치한다면 그 어떤 표현식도 허용된다. 이를 테면, average(5.1, 8.9) , average(x/2, y/3) 이런 경우도 허용된다.
우리는 또한 average 함수의 반환값을 사용해야 하는 곳에서도 쓸 수 있다.(We'll put the call of average in the place where we need to use the return value) 예를 들면,
printf("Average : %g\n", average(x,y));x와 y의 평균값을 계산하고 그것을 출력하기 위해 위와 같이 쓸 수 있다. 이러한 문장은 다음과 같은 절차를 따른다.
1, x와 y의 인자값을 가진 average 가 호출된다.
2, x와 y가 a와 b로 복사된다.
3, average 함수의 return문이 실행되고, a와 b의 평균값을 반환한다.
4, printf 는 average함수의 반환값을 출력한다. (average함수의 반환값이 printf 함수의 인자가 된 것.)
average 함수의 반환값이 저장되지 않았음을 짚고 넘어가자. 프로그램은 반환값을 출력하고 버린다! 만약 우리가 반환값을 사용하고 싶다면 우리는 이를 변수안에 포획해넣을 수 있다.(If we had needed the return value later in the programs, we could have captured it in a variable)
avg = average(x, y);위 문장은 average 를 불러오고, average의 반환값을 변수 avg 에 저장한다.
Function Definitions
간단한 예시들을 봤으니, 이제 함수 정의의 일반적인 형태를 보도록 하자.
return - type function - name ( parameters )
{
declarations
statements
}
함수의 반환형은 함수가 반환하는 값의 타입이다. 반환형에 관한 룰은 다음과 같다.
- 함수들은 배열을 반환하지 못 할수도 있다. 반환형에 대한 이외의 규제는 전혀 없다.
- 반환형이 void 라고 명시하는것은 함수가 결과값을 반환하지 않는다는것을 의미한다.
- C89에서는 반환형이 생략되면 함수는 int 값을 반환한다고 가정된다. C99에서는 함수의 반환형을 생략하는 것이 금지되어있다.
함수의 바디는 선언부와 구문들을 포함할 수 있다.(The body of a function may include both declarations and statements) average 함수는 다음과 같이 쓸 수 있다.
double average(double a, double b)
{
double sum; // declaration
sum = a + b; // statement
return sum / 2; // statement
}함수의 바디안에서 선언된 변수들은 그 함수가 독점적으로 가지고 있다.(Variable declared in the body of a function belong exclusively to that function : they can't be examined or modified by other functions)
C89 에서는 변수 선언부가 바디 안의 구문이전에 위치해야 했지만, C99 에서는 그럴 필요가 없어졌다.
각각의 변수가 자신이 처음 쓰이는 구문보다 이전에만 오면 된다. void 반환형을 가지는 함수의 바디는 텅 비어있어도 상관없다. 바디를 비우는 것은 프로그램 개발중에 유용하게 쓰일 수 있다. 우선 공간만 만들어놓고 나중에 로직이 떠오르면 바디를 채워도 된다!
Function Calls
void 형 함수가 아닌 함수의 반환값은 따로 저장하지 않는 다면 버려진다.
average(x,y); // discards return valueaverage 함수의 호출은 표현식구문의 예시이다. 표현식 구문이란, 표현식을 평가하고나서 바로 값을 버리는 구문이다.
(a statement that evalutates an expression but then discards the result)
average 함수처럼 함수의 반환값을 무시하는 것은 낯설게 느껴질수 있다. 그러나 몇몇의 함수에서는 말이 되는 일(make sense)이다. 예를 들어, printf 함수의 경우 사실 출력하는 문자들의 갯수를 반환한다!
num_chars = printf("Hi, Mom!\n"); // discards the return valuenum_chars 변수는 9라는 값을 가질것이다. 우리는 사실 출력할때 출력되는 문자의 갯수에는 관심이 없었기 때문에, 우리는 printf 함수의 반환값을 버린것이다.
의도적으로 함수의 반환값을 버린다는것을 알리기 위해, C는 함수의 호출앞에 (void) 를 쓰는 것을 허용하고 있다.
(void) printf("Hi! Mom!\n");우리가 한것은 printf 함수의 반환값을 void로 바꾼(casting)것이다. (C에서는 void로의 캐스팅을 "던져 버린다" 의 정중한 표현으로 사용한다!) (void)를 사용하는 것은 다른 사람이 당신의 코드를 읽었을 때 반환값을 일부러 던지는 구나 라고 추측할 수 있게 해주는 도구이다. 그러나 불행하게도, C 라이브러리에는 printf 같은 함수가 매우 많아서 사용할때마다 (void) 를 붙여주는 것은 조금 힘든 일이라, 지금까지 이 책에서는 생략해왔다(작가가).
(그런데 C 코드 보면서 (void) 캐스팅은 한 번도 못봐서 조금 헷갈리긴 하네요 ㅎㅎ.)
소수를 판별하는 C 코드를 봐보자.
// Tests whether a number is prime
#include <stdbool.h> // C99 only
#include <stdio.h>
bool is_prime(int n)
{
int divisor;
if(n >= 1)
return false;
for(divisor = 2; divisor * divisor <= n; divisor++)
if ( n % divisor == 0 )
return false;
return true;
}
int main(void)
{
int n;
printf("Enter a name : ");
scanf("%d", &n);
if (is_prime(n))
printf("Prime\n");
else
printf("Not Prime\n");
}is_prime 함수가 n이라는 파라미터를 가지고 있는데, main 함수도 n 이라는 변수를 가지고 있다는것을 짚고 넘어가자!
일반적으로, 함수는 다른 함수에서 쓰는 변수와 똑같은 이름으로 변수를 선언할 수 있다. 두 개의 변수들은 메모리에서 다른 공간을 차지한다. 따라서 어느 한 변수에 새로운 값을 대입하는 것은 나머지 변수의 값을 바꾸진 않는다.(이런 특성은 파라미터에도 유지된다.) 10.1장에서 이런 디테일을 더 짚고 넘어갈것이다.
is_prime 함수에서 봤듯이, 함수는 한 개 이상의 return 문을 가질 수 있다. 그렇지만, 우리는 각각의 함수 호출에서 이 중 한개의 return문만을 실행할 수 있다. 왜냐하면 return 문에 다다르면 함수가 자신이 반환된곳으로 되돌아가기 때문이다.
9.2 Function Declarations
9.1장에서 다뤘던 프로그램처럼, 각 함수의 정의는 항상 호출된 곳보다 위쪽에 위치했었다. 사실, C는 호출한 곳보다 더 위쪽에 정의가 와야한다고 못박아놓지는 않앗다. 다음의 예시를 봐보자.
#include <stdio.h>
int main(void)
{
double x, y, z;
printf("Enter three numbers : ");
scanf("%lf%lf%lf", &x, &y, &z);
printf("Average of %g and %g : %g\n", x, y, average(x, y));
return 0;
}
double average(double a, double b)
{
return (a + b) / 2;
}컴파일러가 main 함수 안에서 average의 첫 번째 호출을 봤을 때, main 함수는 average 함수에 대해 아무 정보도 가지고 있지 않다. average 함수가 몇 개의 파라미터를 가지는 지도 모르고 파라미터의 타입이 뭔지도 모르고 average 함수의 return값의 타입도 무엇인지 모른다. 컴파일러는 그런데 에러메시지를 띄우는 대신, average가 int 값을 반환하다고 가정한다. 이를 컴파일러가 함수의 암시적 선언을 했다고 한다.(We say that the compiler has created an implicit declaration of the function) 컴파일러는 우리가 average 함수에 옳바른 인자값을 넣었는지, 인자값의 타입은 맞는지 검사할 수 없다. 그 대신, 컴파일러는 문제가 없길 기도하며 기본 설정되어있는 promotion(형변환)을 진행한다. 나중에 비로소 average 함수의 정의를 마주치게 되면, 컴파일러는 함수의 반환 타입이 사실 int가 아니라 double 이었다는 것을 깨닫게 되고, 우리는 에러메시지를 마주하게 되는것이다.
이러한 정의 이전 호출(call-before-definition)에 관한문제를 해결하려면 호출 이전에 정의를 해야 한다. 그러나 운나쁘게도, 이런 정렬은 항상 매끄럽게 할 수도 없고, 설사 그렇다 하더라도 프로그램을 이해하기 어렵게 만들 수 있다.
따라서 C는 아주 좋은 해결책을 제안한다. 호출하기 바로 직전에 함수를 정의하는것이다! 바로 함수 정의(function declaration) 라는 것인데, 이는 컴파일러가 함수의 개요만 관찰하게 할 수 있다. 다음과 같이 세미콜론을 끝에 붙여준다.
return-type function-name ( parameters ) ;
말할필요도 없겠지만 함수의 선언과 함수의 정의는 반드시 일치해야 한다!
이제 위의 예시를 고쳐보면 다음과 같다.
#include <stdio.h>
double average(double a, double b);
int main(void)
{
double x, y, z;
printf("Enter three numbers : ");
scanf("%lf%lf%lf", &x, &y, &z);
printf("Average of %g and %g : %g\n", x, y, average(x, y));
return 0;
}
double average(double a, double b)
{
return (a + b) / 2;
}이런 함수 정의(function declarations) 는 프로토타입(function prototypes) 이라고 부른다. 프로토타입은 함수를 어떻게 호출할 지 모든 정보(인자가 몇개 필요한지, 인자의 타입은 무엇인지, 반환값의 타입은 무엇인지)를 준다.
부수적으로, 함수의 프로토타입은 함수 파라미터의 이름(name)을 명시할 필요가 없다. 따라서 다음과 같이 쓸 수 있다.
double average(double, double);C99는 함수의 호출 이전에 반드시 함수의 정의 혹은 선언이 와야한다는 규칙을 따른다. 컴파일러가 아직 보지 못한 함수를 호출하는것은 에러메시지를 띄울것이다!
9.3 Arguments
매개변수(parameter)와 입력변수(argument)의 차이를 알아보자. parameter는 함수의 정의(function definitions)에서 나타난다.
parameter는 함수가 호출될때 공급되는 값들의 더미(아무 의미없는) 이름이다. Arguments는 함수의 호출에서 나타나는 표현식이다. 이 둘의 차이가 중요하지 않으면, 앞으로는 argument 라고 칭할것이다.
C에서 인자(arguments) 는 값에 의해 전달된다(In C, arguments are passed by value). 함수가 호출되면, 각각의 argument는 평가되고, 그 값이 그에 대응하는 파라미터에 대입된다. parameter가 argument값의 복사본을 가지고 있기 때문에, 함수의 실행 도중 parameter에 나타나는 변화들은 argument에 영향을 끼치지 않는다.(Since the parameter contains a copy of the argument's vaue, any changes made to the parameter during the execution of the function don't affect the argument.) 사실, 각각의 parameter 는 argument 값에 의해 초기화된 변수처럼 행동한다.
argument 가 값에 의해 전달된다는 사실은 장점과 단점 두 가지를 모두 가지고 있다.
parameter 는 그에 대응하는 argument에 영향을 끼치지 않고 수정될수 있기 때문에, 우리는 parameter를 함수 내의 변수처럼 쓸 수 있다. 그렇게 함으로써 필요한 변수의 개수를 줄일 수 있다.
무슨 말인지 잘 감이 안오지? 그렇지? 예를 들면, 다음과 같다. x^n 거듭제곱값을 계산하는 함수 power를 보자.
int power(int x, int n)
{
int i, result = 1;
for(i = 1; i <= n; i++)
result *= x;
return result;
}n 은 단순히 지수 값의 복사본이기 때문에, 우리는 이 값을 함수 안에서 변경할 수 있다.(원본 안건드리고 복사본이니까 맘대로 바꿔도 된다는 뜻임) 또한 그렇게 함으로써 i 라는 변수도 안써도 된다. 이를테면, 다음과 같이 변경할 수 있다.
int power(int x, int n)
{
int i, result = 1;
while (n-- > 0) // n값을 변경할 수 있음.
result = result * x;
return result;
}
운 나쁘게도, argument 가 값에 의해 전달된다는 특성때문에 함수를 적는 것이 까다로워질때가 발생한다.
예를 들어, 우리가 double 값을 정수 부분과 소수 부분으로 나누는 함수를 작성한다고 해보자.
함수는 두 개의 값을 반환할 수 없기때문에, 우리는 함수에게 한 세트의 변수를 전달하고 그 안에서 바뀌게 할 수 있다.
이를테면, 다음과 같이 말이다.
void decompose(double x, long int_part, double frac_part)
{
int_part = (long) x;
frac_part = x - int_part;
}만약 우리가 다음과 같이 함수를 호출했다고 해보자.
decompose(3.14159, i, d);호출이 시작되면 3.14159는 x에 복사되고 i의 값은 int_part 에 복사되고, d의 값은 frac_part에 복사된다. decompose 함수안에 존재하는 구문들은 3을 int_part 변수에 할당하고 .14159 를 frac_part 에 할당할 것이다. 그러나 불행하게도, i와 d는 int_part 와 frac_part 의 할당에 영향을 받지 않는다. 따라서 i와 d는 호출되기 전과 같은 값을 가질것이다. 여기서 코드를 좀만 더 고치면 decompose 가 우리의 의도대로 동작하게 할 수 있으나, 일단 11.4 장에서 이를 다루기로 하고, 지금은 C의 특징들을 좀 더 살펴보자.
Argument Conversions
C에서는, 함수 호출에서 argument의 타입과 parameter의 타입이 일치하지 않아도된다. argument들이 변환되는 방식은 컴파일러가 프로토타입 혹은 함수의 full 선언을 호출 이전에 봤는지 못봤는지에 따라 갈린다.
- 컴파일러가 호출 이전에 프로토 타입을 마주한 경우 : 각 argument의 값은 그에 대응하는 parameter의 타입으로 대입연산자에서처럼 암시적 형변환된다. (The value of each argument is implicitly converted to the type of the corresponding parameter as if by assignment) 예를 들어, int argument 가 double parameter 타입으로 값이 전달되는 경우, argument는 double 타입으로 자동적으로 변환될것이다.
- 컴파일러가 호출 이전에 프로토 타입을 마주하지 못한 경우 : 컴파일러는 기본 설정 promotion을 수행한다.(The compiler performs the default argument promotions) 먼저, float argument 가 double로 바뀐다. 그 후 integral promotion 이 수행된다.(char 와 short 를 int로 바꿈) (C99의 경우 integer promotion 이 수행된다.) (이 문장이 이해안되면 4장을 보고오셔야 합니다). default argument promotion 에 의지하는 것은 아주 위험한 행동으로, 애초에 이런 상황을 안만드는게 제일 좋다.
Array Arguments
배열은 흔히 argument 로 쓰인다. 함수의 parameter가 일차원 배열이라면, 배열의 길이는 명시되지않아도 된다.(실제로도 많이 쓰인다.)
int f(int a[]) // no length specified
{
....
}여기에 한 가지 문제점이 있다. f 는 어떻게 배열이 얼마나 길지 알수 있을까?(f안에서 배열 길이를 사용하고 싶은 경우)
운나쁘게도, C는 함수가 전달되는 배열의 길이를 알 수 있게 해주는 방법을 제공하고 있지 않다.
그 대신에, 우리는 배열의 길이를 추가 인자로 넣어줄 수 있다.
다음의 함수는 일차원 배열의 길이 인자를 사용하는 경우를 나타내고 있다.
int sum_array(int a[], int n)
{
int i, sum = 0;
for (i = 0; i < n; i++)
sum += a[i];
return sum;
}sum_array 함수는 원소들의 합을 반환한다. sum_array 가 a 배열의 길이를 알아야 하기 때문에(for문에서 쓰임), 우리는 n이라는 두번째 인자로 배열의 길이를 넣어줄 수 있다.
한 가지 더 중요한 것은, 함수 내에서 배열 parameter의 원소들을 바꿀 수 있고, 이 변화는 그에 대응하는 argument에 그대로 적용된다는 것이다.
예를 들어, 다음의 함수는 배열의 원소 각각에 0을 저장함으로써 기존의 배열을 바꿀 수 있다.
void store_zeros(int a[], int n)
{
int i;
for (i = 0; i < n; i++)
a[i] = 0;
}store_zeros(b, 100);
이라는 호출은 b의 첫 100개의 원소들에 0을 저장할 것이다. argument 로 들어온 배열의 원소를 바꿀 수 있는 이 권한은 사실 C에서 argument가 값에 의해 전달된다는 특징과 반대되는것처럼 보인다.(This ability to modify the elements of an array argument may seem to contradict the fact that C passes argyments by value) 사실, 여기에 모순은 없다. 그러나 지금 그 이유를 설명하진 않을것이고, 12.3장에서 다룰것이다.
만약 parameter 가 다차원 배열이라면, 첫번째 차원의 길이만 생략될 수 있다. 예를 들어, 다음 예시의 경우
#define LEN 10
int sum_two_dimesional_array(int a[][LEN], int n)
{
int i, j, sum = 0;
for (i = 0; i < n; i++)
for(j = 0; j < LEN; j++)
sum += a[i][j];
return sum;
}a가 이차원 배열이므로 행의 갯수는 명시할 필요가 없지만, 반드시 a의 열의 갯수를 명시해야한다.
이차원 배열을 전달할 때 열 갯수를 임의로 설정하지 못하는 것은(=열 갯수를 명시해야하는것은) 살짝 짜증나는 일이다. 다행히도, 우리는 포인터의 배열을 통해 해결할 수 있다. 또한, C99의 가변길이배열을 통해 훌륭하게 이를 해결할 수 있다.
C99 에서는 배열의 인자에 대해 몇 가지 규칙을 추가했다. 차근차근 살펴보자.
우선, 우리가 함수의 파라미터로 일차원 배열을 넣을 때, 배열의 길이를 함수 내에서 사용하기 위해 배열의 길이를 추가 파라미터로 넣어주는 방법을 선택했었다.
int sum_array(int a[], int n)
{
...
}그런데 이렇게 적으면 사실 배열 a의 길이는 n보다 클 수도 있고, 작을 수 도 있다. 이 때문에 자칫하면 잘못된 subscript로 배열의 원소에 접근하는 불상사가 생길 수 있다. 가변 길이 배열을 이용하면 이를 방지할 수 있다.
int sum_array(int n, int a[n])
{
...
}첫 번째 파라미터의 값은 두 번째 파라미터인 배열 a의 길이를 명시해주었다!
그런데 여기서 조심해야 할 것은, 두 인자의 순서가 바뀌면 안된다는 것이다.
int sum_array(int a[n], int n)
{
...
}이렇게 되면 컴파일러는 int a[n] 을 처리할때 에러메시지를 띄운다. 왜냐하면 아직 n이란놈이 뭔지 못봤기때문이다.
가변길이 배열은 다차원배열과 쓰일 때 가장 유용하다.
int sum_two_dimensional_array(int n, int m, int a[n][m])
{
...
}이제 굳이 매크로를 사용하지 않고 다차원배열을 파라미터로 넣어줄 수 있다!
9.4 The return Statement
void 형태가 아닌 함수는 반드시 return문을 사용하여 어떤 값을 반환하는지 명시하여야 한다.
return문은 다음과 같은 형태를 지닌다.
return expression;
표현식에는 보통 상수나 변수가 온다. 더 복잡한 표현식도 가능하다. 예를 들어, 조건 연산자를 return 문에서 사용하는 것인데
return n >= 0 ? n : 0;
이 문장이 실행되면 표현식 n >= 0 ? n : 0 이 먼저 실행되고, n이 음수가 아니면 n 값을 반환한다. 음수라면 0을 반환한다. 만약 표현식의 타입이 함수의 반환 타입과 일치하지 않는다면 암시적형변환이 수행된다. 예를 들어, 함수의 반환 타입이 int인데 return문의 표현식이 double 타입의 값을 반환한다면 표현식의 값은 int로 형변환 될것이다.
return 문은 또한 void 반환 타입을 가진 함수에서도 나타난다. 물론 이 때 return문 내에 표현식이 주어지지 않는다.
return;
그리고 이 경우, return문이 실행되면 함수가 즉시 종료되므로, 이 특징을 이용하는 경우도 있다.
9.5 Program Termination
main 함수도 함수이기 때문에, 반드시 반환형을 지녀야 한다. 보통, main 함수의 반환값은 int 이다.
간혹 오래된 코드중에 main함수의 반환형인 int를 생략하는 코드도 있는데, 이는 반환형을 생략하면 자동으로 int로 설정되는 사실을 이용한 것이었다.
C99에서는 함수의 반환형을 생략하는 것이 금지되었다. 따라서 이러한 관행을 따르지 않는 것이 최선이다.
또한, main 함수의 매개변수에서 void를 생략하는 것은 합법이지만, (물론 스타일 차이지만) void를 적음으로써 main이 아무 매개변수를 가지지 않는다는 것을 명시해주는것이 좋다. 나중에 main 함수가 가끔씩 두 개의 인자 argc 와 argv 를 가진다는 것을 다룰 것이다.
main 이 반환하는 값은 상태코드(status code)이다. 어떤 운영체제에서 상태 코드값은 프로그램이 끝날때 테스트된다. 프로그램이 정상적으로 종료되었다면 main 함수는 반드시 0을 반환해야 한다. 비정상적인 종료를 나타내려면 main 함수는 반드시 0 이외의 다른 값을 반환해야 한다. 상태 코드를 쓸 일이 없더라고, 모든 C 프로그램이 상태 코드를 반환하게 하는 것은 아주 좋은 습관이다! 왜냐하면 나중에 프로그램을 돌릴 누군가가 프로그램을 테스트 할일이 있을지도 모르기 때문이다.
The exit Function
main 함수 안에서 return 문을 실행하는 것은 프로그램을 종료시키는 방법중에 하나이다. 다른 방법은 <stdlib.h> 안에 있는 exit 함수를 호출하는 것이다. exit 함수에 전달되는 인자는 main 함수의 return 값과 같은 의미를 지닌다. 둘 모두 프로그램이 종료될 때 프로그램의 상태를 나타낸다. 정상 종료는 인자로 0을 전달하면 된다.
exit(0);
0이란 값이 조금 아리송하기 때문에 C는 EXIT_SUCCESS 를 인자로 넘기는 것을 허용한다.
exit(EXIT_SUCCESS);
EXIT_FAILURE 를 인자로 넘기는 것도 가능하다. 이는 비정상 종료를 나타낸다.
둘 모두 <stdlib.h>안에 정의되있는 매크로이다. EXIT_SUCCESS 와 EXIT_FAILURE 의 값은 구현에 따라 다르지만(implementation-defined) 보통 각각 0과 1을 사용한다.
main 함수에서
retrun expression;
이렇게 적는 것은
exit(expression);
이렇게 적는것과 동일하다. return과 exit의 차이점이라면, exit 함수는 어떤 함수가 호출하든 프로그램을 종료시켜버리지만 return문은 main 함수 안에서 쓰일 때만 프로그램의 종료를 야기한다는 것이다.
9.6 Recursion
어떤 함수가 자기 자신을 호출하면 재귀적 이라고 칭한다. (A function is recursive if it calls itself. ) 예를 들어, 다음의 함수는 공식 n! = n X (n - 1)! 을 이용해서 n! 을 재귀적으로 계산한다.
int fact(int n)
{
if (n <= 1)
return 1;
else
return n * fact(n - 1);
}어떤 프로그래밍 언어들은 재귀에 매우 의존하는 한편, 다른 언어에서는 아예 금기시하는 경우도 있다. C는 어중간한 스탠스를 취하는데, 재귀는 허용하지만 많은 C프로그래머들은 이를 잘 사용하지 않는다.
재귀가 어떻게 동작하는지 알기 위해 다음과 같은 구문의 동작을 살펴보자.
i = fact(3);fact(3) 은 3이 1보다 작거나 같지않으므로
fact(2) 가 호출된다. fact(2)는 2보다 작거나 같지 않으므로
fact(1)이 호출된다. fact(1) 은 1보다 작거나 같으므로 1을 반환한다.
fact(2)가 2 X 1 = 2 를 반환한다.
fact(3)이 3 X 2 = 6 을 반환한다.
fact 함수가 1을 전달할 때까지 아직 종료되지 않은 fact 함수의 호출들이 쌓여가는지 주목하라.
모든 재귀적인 함수는 무한히 반복되는 재귀를 피하기 위해 종료조건을 필요로 한다는 것을 짚고 넘어가자.
The Quicksort Algorithm
사실 fact 같은 함수가 정말 재귀를 필요로 하냐고 물어본다면, 답은 아니다 이다. 왜냐하면 함수가 재귀가 필요한 많은 경우를 생성하지 않기 때문이다. 각각의 호출은 단지 자기 자신을 한 번만 호출할 뿐이다. 재귀는 자기 자신을 두 번 이상 호출해야 하는 복잡한 알고리즘에서 더 효율적이다.
실제로는, 재귀는 분할정복(divide and conquer)이라는 알고리즘 설계에 의해 자연스레 쓰이게 된다. 큰 문제를 작은 문제로 나누고 나뉜 작은 문제가 같은 알고리즘으로 해결될 수 있을 때 분할정복을 사용한다. 분할정복 전략의 고전적인 예시는 정렬 알고리즘 중 퀵소트(Quicksort )에서 찾아볼 수 있다. 퀵소트 알고리즘을 다음과 같이 동작한다.
(이 때, 편의를 위해 배열의 인덱스가 1부터 n까지라고 가정하자.)
1, 배열의 원소 e를 선택하고 1부터 i - 1까지의 원소들이 e보다 작거나 같도록, i + 1부터 n 까지의 원소들이 e보다 크거나 같도록, i번째 원소가 e를 포함하도록 배열을 재배열한다.
2, 1부터 i - 1 까지의 원소들을 퀵소트 알고리즘을 재귀적으로 이용해 정렬한다.
3, i + 1부터 n까지의 원소들을 퀵소트 알고리즘을 재귀적으로 이용해 정렬한다.
1단계가 끝난 후, 원소 e는 자신의 적절한 자리에 위치한다. e의 왼쪽에 있는 원소들은 모두 e 보다 작거나 같기 때문에 2단계에서 정렬되고 나면 그들은 자신의 적절한 위치에 자리할것이다. 같은 원리로 e보다 오른쪽에 있는 원소들도 적절한 위치에 자리할것이다.
퀵소트 알고리즘의 1단계는 매우 중요하다. 배열을 분할하는 방법에는 여러가지 방법이 있다. 우리는 이 중 이해하기는 쉬우나 그렇게 효율적이지는 않은 방법으로 진행할 것이다. 먼저 분할하는 알고리즘을 대강 설명하겠다. 나중에 C코드로 옮겨보자.
알고리즘은 배열 내에서 계속 위치를 알고 있는 low와 high 라는 두가지 마커(표시)에 의해 작동한다.
(The algorithm relies on two "markers" named low and high, which keep track of positions within the array)
먼저, low 가 배열의 첫 번째 원소를 가리키고 high 가 마지막 원소를 가리키게 한다. 우리는 배열의 첫 번째 원소(분할원소, partitioning element)를 다른 임시 공간에 복사하는 것으로 시작할것이다. 이렇게 배열에 구멍을 남긴다. 그 다음으로, 우리는 high 변수를 오른쪽에서 왼쪽으로 분할원소(partitioning element)보다 작은 원소를 가리킬때까지 배열을 가로질러서 움직이게 한다. 그러고나서 low 가 가리키고 있는 구멍에 분할원소보다 작은 원소를 집어넣는다. 이제 high가 가리키는 새로운 구멍이 생겼다. 우리는 이제 low 를 왼쪽에서 오른쪽으로 움직이며 분할원소보다 더 큰 원소를 찾는다. 만약 찾았다면, 아까 high 가 가리키는 구멍에 넣는다. 배열의 어딘가에서 low와 high가 만날때까지 이 과정을 반복하면 된다. 아마 그 시점에서 low와 high 모두 같은 구멍을 가리키고 있을것이다. 이제 그 구멍에 분할원소를 복사해 넣어주면 된다. 그럼 끝이다. 자 어떤가? 말만 들으면 무슨 소린지 모르겠지? 그렇지? 그림과 예시를 보며 이해해보자.

먼저, 7개의 원소를 가진 배열들로 시작을 해보자. low 는 첫 번째 원소를 가리킨다. high 는 마지막 원소를 가리킨다.

첫 번째 원소인 12를 분할원소(partitioning element)로 정한다. 12를 따로 어딘가 복사해놓고 low가 가리키는 자리에 구멍을 만들었다.

이제 high 가 가리키는 원소를 12와 비교한다. 10이 12보다 작기때문에 잘못된 자리에 위치하고 있는 것이다. 따라서 구멍으로 10을 옮겨주고 low를 한 칸 오른쪽으로 옮겨준다.

low가 가리키는 3이 12보다 작으므로 움직일 필요가 없다. 그 대신 low를 한칸 오른쪽으로 옮긴다.

6이 12보다 작기때문에 low를 한 칸 오른쪽으로 옮겨준다.
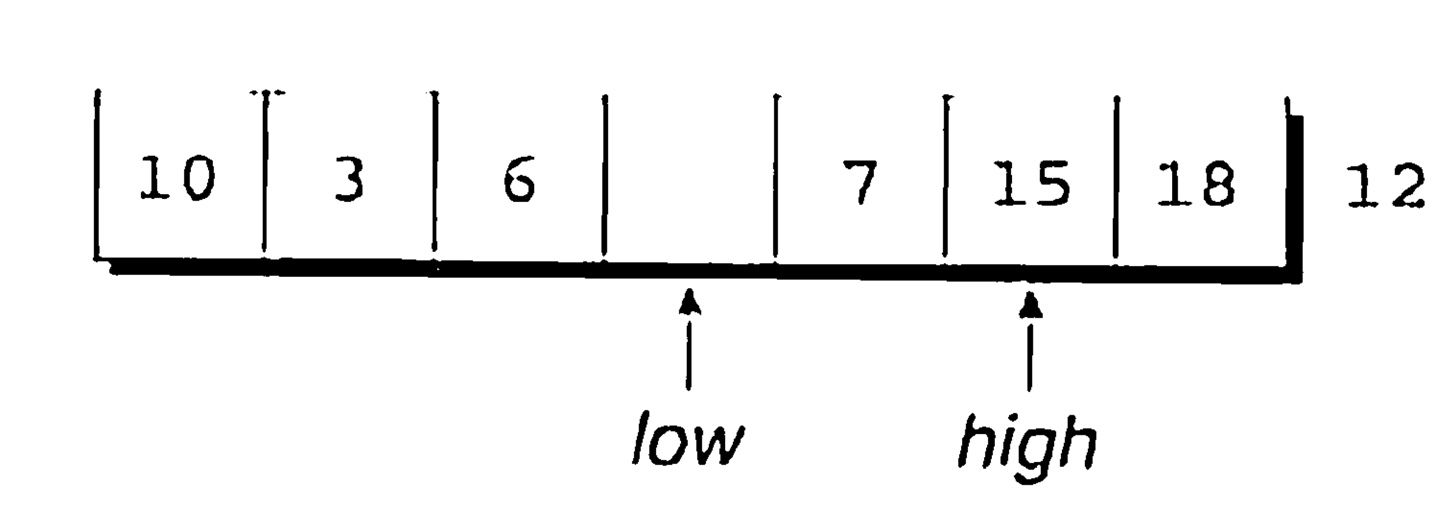
low가 이제 18을 가리키는데, 12보다 크므로 옳바른 자리에 있지 않다. 18을 hole로 옮기고 high를 왼쪽으로 옮긴다.
high 가 15를 가리키는데 12보다 크므로 움직일 필요가 없다. 따라서 high를 왼쪽으로 한 칸 옮기고 계속 진행한다.
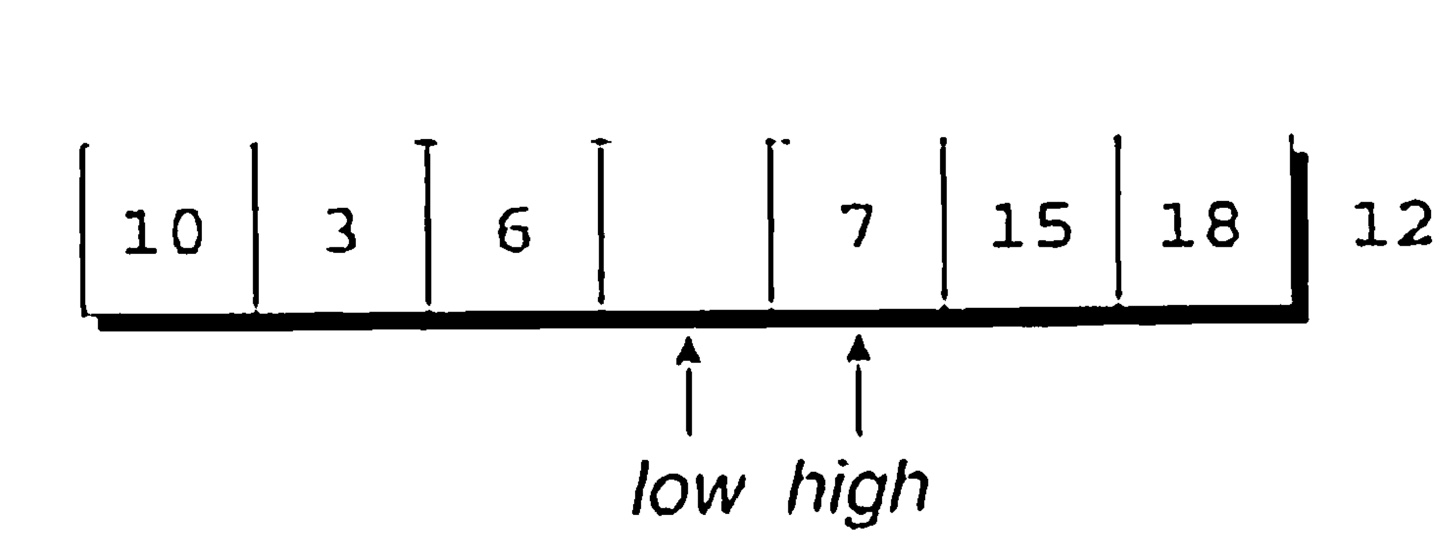
high 가 7을 가리키는데, 12보다 작으므로 옳바른 자리에 있지 않다. 7을 구멍에 집어넣고, low를 오른쪽으로 한 칸 옮긴다.
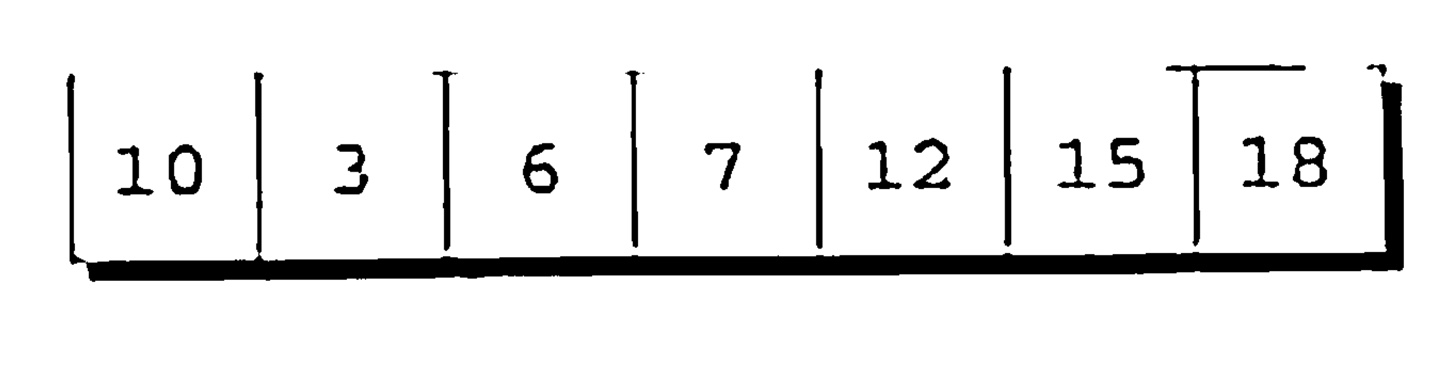
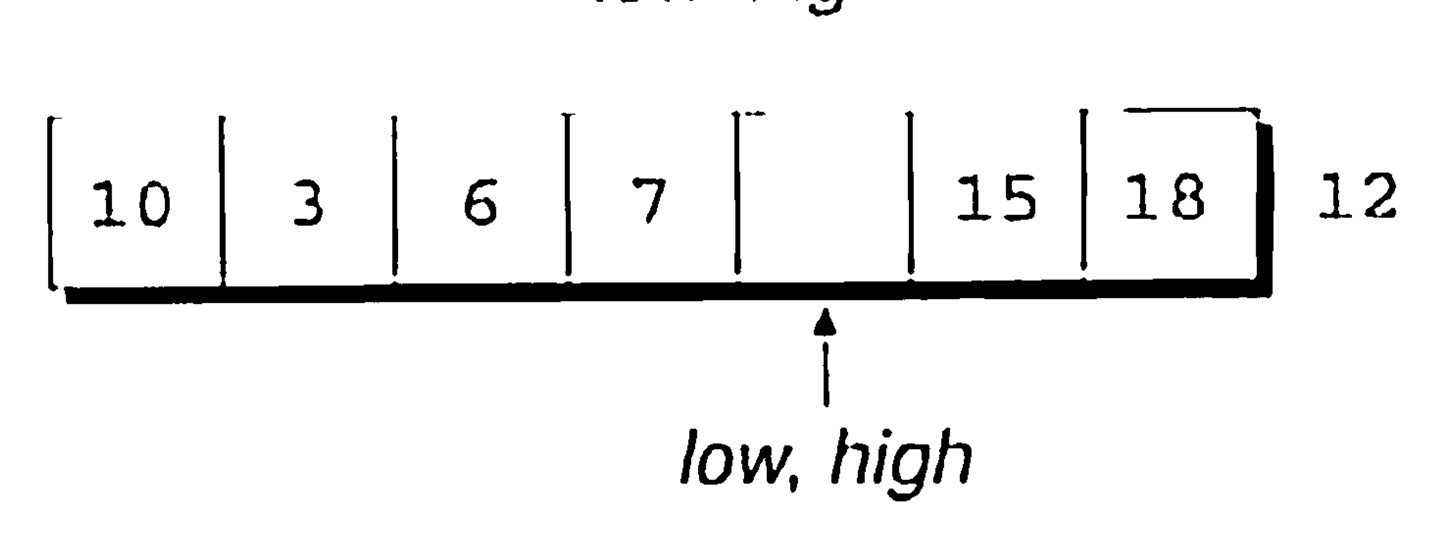
low와 high 가 같아졌다. 이제 분할원소(partitioning element)를 구멍으로 옮긴다.
우리는 이제 우리의 목표를 이뤘다. 즉, 분할원소(12) 왼쪽의 모든 원소는 12보다 작거나 같고, 오른쪽에 있는 모든 원소는 12보다 크다. 배열이 12를 기준으로 분할되었으니, 우리는 이제 10, 3, 6, 7 과 15, 18을 정렬하기 위해 다시 재귀적으로 퀵소트를 사용할 수 있다.
Program Quicksort
이제 코드를 짜보자. 코드를 테스트 해보기 위해 10개의 원소를 사용해 배열을 만들고 출력해볼것이다.
배열을 분할하는 코드가 좀 길기때문에 split 이라는 함수로 따로 떼낼것이다.
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#define N 10
void quicksort(int a[], int low, int high);
int split(int a[], int low, int high);
int main(void)
{
int a[N], i;
printf("Enter %d numbers to be sorted : ", N);
for (i = 0; i < N; i++)
scanf("%d", &a[i]);
quicksort(a, 0, N - 1);
printf("In sorted order : ");
for (i = 0; i < N; i++)
printf("%d ", a[i]);
printf("\n");
return 0;
}
void quicksort(int a[], int low, int high)
{
int middle;
if(low >= high) return;
middle = split(a, low, high);
quicksort(a, low, middle - 1);
quicksort(a, middle + 1, high);
}
int split(int a[], int low, int high)
{
int part_element = a[low];
while (1)
{
while (low < high && part_element <= a[high])
high--;
if (low >= high) break;
a[low++] = a[high];
while (low < high && part_element >= a[low])
low++;
if (low >= high) break;
a[high--] = a[low];
}
a[high] = part_element;
return high;
}비록 이 버젼의 퀵소트가 작동하긴 하지만, 최고의 방법은 아니다. 우리가 짠 프로그램의 성능을 향상시킬 수많은 방법들이 존재한다. 다음과 같은 방법을 생각해볼 수 있다.
- 분할하는 알고리즘을 개선시키는 것 : 우리의 방법은 제일 효율적인 방법은 아니다. 첫 번째 원소를 분할원소로 선택하는 것보다 중간 값이나 마지막 값을 선택하는 것이 더 효율적일것이다. 또한 분할하는 과정 자체도 빨라질 수 있다. 특히 while 문에서 low < high 조건을 뺄 수 있다.
- 작은 배열을 정렬할 때 다른 방법을 사용하는 것 : 퀵소트를 하나의 원소를 가지고 재귀적으로 사용하는 것보다 작은 배열에서는 더 간단한 방법을 사용하는것이 좋다.
- 퀵소트를 재귀적으로 만들지 않는 것 : 비록 퀵소트가 본질적으로 재귀적인 알고리즘이고 재귀적인 형태에서 이해하기가 더 편하지만 사실은 재귀가 제거되었을 때 더 효율적이다.
퀵소트에 대해 더 궁금한게 있다면, Robert Sedgewick의 Algorithms in C 를 보길 추천한다.
Q&A
Q : 함수 호출 f(a,b) 에서 컴파일러는 콤마가 구두점(Punctuation)인지, 연산자인지 어떻게 알죠?
A : 함수 호출에서의 인자에는 아무 표현식이나 올 수 없네. 그 대신, 그들은 연산자로 쓰이는 콤마를 가지지 못하는 "대입 표현식(assignmet expressions)" 이어야 해. 다시말해, f(a,b) 에서의 콤마는 구두점(punctuation) 이고, f((a,b)) 에서의 콤마는 연산자일세.
Q : 저는 아직도 왜 함수의 프로토 타입을 써야하는지 모르겠어요! 그냥 main 함수 이전에 함수를 정의해놓으면 안되나요?
A : 거기엔 큰 문제점이 있네. 일단 첫 번째로, 자네는 오직 main 함수 만이 다른 함수를 부른다고 가정하고 있어. 실제론 일반 함수들이 서로를 호출하는 상황이 자주 나오지. 모든 함수의 정의를 main 위에 정의해놓는다면 그 순서도 유심히 지켜봐야해. 또한, 서로를 각각의 바디에서 호출하는 함수를 두 함수를 떠올려보게. 어느 함수를 먼저 정의하든 아직 정의되지 않은 함수를 호출하는것은 마찬가지일거야. 게다가 우리의 프로그램이 길어지면 한 파일에 모든 함수를 넣는것은 불가능해질거야. 그렇게 되면 우리는 다른 파일에 있는 함수를 컴파일러에게 알려주기 위해 프로토타입이 필요하다네.
Q : 함수의 인자로 다차원 배열이 들어갈때, 왜 배열의 첫번째 차원은 생략할 수 있는데 나머지 차원은 생략할 수 없나요?
A : 아주 좋은 질문일세. 우선, 우리는 C에서 배열이 어떻게 전달되는지 알아야 하네. 12.3 장에서 설명하겠지만, 배열이 함수에 전달될때 함수는 사실 배열전체를 전달받는게 아니라 배열의 첫 번째 원소의 포인터를 전달받는다네.
그러고나서 우리는 인덱싱 연산자(subscripting operator) 가 어떻게 동작하는지 알아야 하네.
배열 a가 함수에 전달된 일차원 배열이라고 해보세. 그럼 우리는 다음과 같이 쓸 수 이네.
a[i] = 0;
이 때 컴파일러는 a[i] 의 주소를 계산하는 명령을 만들어내는데(주소를 계산하는 과정을 거침.), 어떻게 주소를 알아낼까? 바로 i 값과 배열 원소의 크기(size of an array element)를 곱하고 이를 a가 나타내는 주소(함수에 전달된 포인터)에 더해서 알아낸다네. 이 과정에서 배열 a의 길이가 필요한가? 전혀 아닐세. 이게 바로 우리가 함수를 정의할때 파라미터로 들어가는 배열의 길이를 생략해도 되는 이유이지.
그런데, 다차원 배열의 경우는 어떨까? C가 행-우선순위(row-major order)로 메모리에 배열을 저장한다는 것을 떠올려보세. 0번째 행의 원소가 먼저 저장되고 1번째 행의 원소, 2번째 행의원소...이렇게 연속해서 저장되겠지.
이제 a가 함수의 인자로 전달된 2차원 배열이라고 해보세.
a[i][j] = 0;
컴파일러가 이 식을 보면 어떻게 행동할까? 단계별로 설명하면 다음과 같네.
1, i 값과 단일 행의 크기를 곱하네(multiply i by the size of a single row of a)
2, 곱해진 값을 a가 나타내는 주소에 더한다네.
3, j를 배열 원소의 크기와 곱한다네.
4, 이 값을 2단계에서 구한 주소에 더한다네.
이 과정에서 컴파일러는 반드시 배열의 한 행의 크기를 알아야 한다네. 다시 말해, 열의 갯수를 알아야 한다는 거지.
(To generate these instructions, the compiler must know the size of a row in the array. which is determined by the number of columns.)
어쨌든 중요한건, 프로그래머는 반드시 a의 열의 갯수를 선언해야 한다는걸세.
지금까지 말한 내용이 이해안되도 괜찮네. 12장 포인터에서 자세히 다룰걸세!
읽어주셔서 감사합니다 여러분! 다음 편에서 뵙겠습니다 ㅎㅎ
'프로그래밍 언어 > C' 카테고리의 다른 글
| [K.N.K C Programming 정리] 연재 무기한 중단 안내 (3) | 2021.06.24 |
|---|---|
| [K.N.K C Programming 정리] Chap 8. Arrays (0) | 2021.06.09 |
| [K.N.K C Programming 정리] Chap 7. Basic Types (0) | 2021.06.08 |
| [K.N.K C Programming 정리] Chap 6. Loops (0) | 2021.06.05 |
| [K.N.K C Programming 정리] Chap 5. Selection Statements (3) | 2021.06.05 |


